


Most teams capture telemetry and blobs at the edge with a collect → transport → store model: data is pushed through gateways and pipelines, then shipped upstream into centralized databases.
But as pipelines multiply, transport becomes the product—connectors, queues, ETL, retries—each adding outages, egress costs just to route centralized data to where it's needed, and a team just to keep it running.
Eventually, teams hit the next wall: data volumes explode and formats diversify—video, images, logs, and high-frequency telemetry from dozens of sources—so it stops fitting cleanly into pre-built solutions and is then dumped into S3 object storage as the catch-all. But now discovery is mostly prefix browsing: meaning gets crammed into filenames, and compliance questions like "show me tamper-evident history for asset X over the past 18 months" turn into a slow, manual hunt.
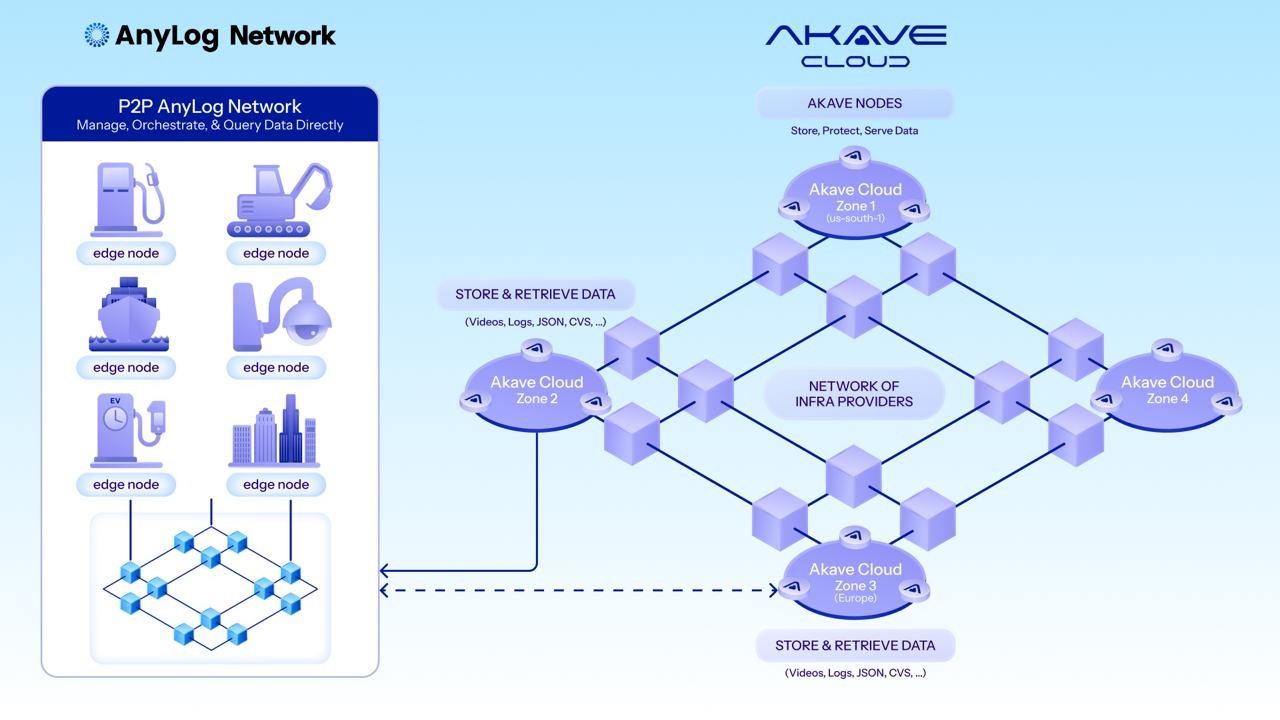
Akave × AnyLog replaces the complex pipelines with an in-place system that only requires queries and requested data to move across the network.
Rather than centralizing data, AnyLog deploys lightweight agents on edge nodes to form a unified namespace across distributed infrastructure. Telemetry stays in local databases, and blobs can stay local with Akave O3—or be tiered to Akave Cloud based on retention policies. Either way, users and applications can query the distributed data sources with SQL as if it lived in one centralized system. This functionality spans across SQL databases and object buckets, extending discovery beyond prefix-based listing to rich, metadata-driven search. The solution also eliminates egress costs entirely.
We call our solution a portable Edge Data Fabric with tamperproof provenance.
Orchestration at the Edge, Provenance on Chain
AnyLog is the real-time data services layer. Its Edge Data Fabric (EDF) and Unified Namespace (UNS) turn physically distributed IoT nodes into one queryable fabric, with queries pushed down to where data is generated.
A facility with 200 sensors across 40 machines, each running its own local database, queries as if it were a unified data source. Ingestion rules, analytics, and business logic execute at the source. Queries run at the edge; only results move across the network.
AnyLog can index blob and object references—images, video, logs—alongside structured records. The payload lives in storage, but the row you query holds the identifier: hash, file name, or bucket key. Discovery happens via SQL (device, time window, event type), then retrieval is a direct fetch using the referenced ID. You stop hunting prefixes.
AnyLog's native MCP (Model Context Protocol) server exposes the same query interface to AI. LLMs or agents can generate reports from the network. Deployments can enforce access controls and auditability consistent with enterprise requirements.
Akave Cloud is the durable offload layer. It is S3-compatible and flat-rate, and it adds verifiable receipts on top of object storage: immutable content identifiers (CIDs) tracked per object plus onchain audit logs for storage actions. For Filecoin-backed tiers, Proof of Data Possession (PDP) adds cryptographic evidence that stored data still exists and is retrievable, independent of Akave nodes.
The handoff is the S3 API, so your offload pipeline stays portable.
Persistent Storage With Onchain Receipts
When data outgrows the edge buffer—compliance retention, AI training sets, long-term audits—AnyLog nodes automatically offload to Akave via the S3 API. No new protocol. No custom adapter.
Akave pay-as-you-go is $14.99/TB/month with no egress or API request fees. Beyond cost certainty, it gives you an audit trail you can verify. Immutable CIDs are tracked per object, and storage actions (uploads, reads, access permissions) are immutably logged onchain.
Given an object's CID and the corresponding onchain entry, an auditor can validate the receipt independently, without relying solely on vendor-controlled logs.
For Filecoin-backed tiers, PDP adds a second layer of verification. It uses cryptographic challenge-response to prove a provider still holds the data and can serve it, without downloading the full object. Data is encrypted, erasure-coded, and distributed across providers, with durability determined by configured redundancy.
For regulated AI and critical infrastructure programs under audit pressure, those receipts and possession proofs are stronger evidence than internal logs alone.
What This Looks Like in Practice?
A grid operator runs AnyLog nodes at substations and solar generation sites. Sensors detect a load imbalance. With a single SQL query through AnyLog, the application evaluates live conditions and joins in historical baselines from Akave; the resulting event package is then written to Akave for retention. The stored object gets a CID and an onchain log entry. No folder paths reconstructed. No custom retrieval script.
Six months later, when a regulator requests evidence on that event: the operator retrieves the object, hashes it, and matches it to the onchain receipt. That shows the record existed at that time and has not been altered. The audit doesn't depend on anyone's memory of what the system logged or where the file was stored.
The Record Either Exists or It Doesn't
Run one workload through this stack. Validate the proof chain. Know the record is there before you need it.
- AnyLog documentation and download: anylog.network
- Akave Cloud account (S3-compatible, zero egress fees): cloud.akave.ai
- Technical documentation: docs.akave.xyz
FAQs
What is edge data fabric and how does it differ from traditional data pipelines?
Traditional pipelines centralize data by pushing it through gateways, connectors, and ETL processes into upstream databases. Edge data fabric keeps data where it's generated and creates a unified namespace across distributed nodes. AnyLog's Edge Data Fabric lets you query physically distributed IoT nodes with SQL as if they were one system—only query results move across the network, not raw data.
How does AnyLog's Unified Namespace work with distributed sensors and devices?
AnyLog deploys lightweight agents on edge nodes that form a queryable fabric. A facility with 200 sensors across 40 machines, each running its own local database, queries as if it were a unified data source. Ingestion rules, analytics, and business logic execute at the source. AnyLog indexes blob and object references alongside structured records, enabling SQL-based discovery by device, time window, or event type.
What happens when edge data needs long-term retention or compliance storage?
When data outgrows the edge buffer—for compliance retention, AI training sets, or long-term audits—AnyLog nodes automatically offload to Akave Cloud via the S3 API. No new protocol or custom adapter required. Data can stay local with Akave O3 or tier to Akave Cloud based on retention policies while remaining queryable through the same unified namespace.
What are onchain receipts and why do they matter for audits?
Every object stored on Akave receives an immutable content identifier (CID) and an onchain log entry recording storage actions (uploads, reads, access permissions). Given an object's CID and the corresponding onchain entry, an auditor can validate the receipt independently—without relying on vendor-controlled logs. This provides tamper-evident proof that a record existed at a specific time and hasn't been altered.
What is Proof of Data Possession (PDP) and how does it work?
PDP uses cryptographic challenge-response to prove a storage provider still holds data and can serve it, without downloading the full object. For Filecoin-backed tiers, PDP adds a second layer of verification beyond CIDs. Data is encrypted, erasure-coded, and distributed across providers. For regulated AI and critical infrastructure under audit pressure, possession proofs are stronger evidence than internal logs alone.
How does this solution eliminate egress costs?
AnyLog keeps data at the edge and only moves query results across the network. Akave Cloud charges $14.99/TB/month with zero egress and zero API request fees. Combined, the architecture eliminates the egress costs that accumulate when centralizing data through traditional pipelines and repeatedly moving it between storage and compute.
Can AI agents and LLMs query the edge data fabric?
Yes. AnyLog's native MCP (Model Context Protocol) server exposes the same query interface to AI. LLMs or agents can generate reports from the distributed network while deployments enforce access controls and auditability consistent with enterprise requirements.
What does this look like in a real deployment?
A grid operator runs AnyLog nodes at substations and solar generation sites. When sensors detect a load imbalance, a single SQL query evaluates live conditions and joins historical baselines from Akave. The event package is written to Akave for retention with a CID and onchain log entry. Six months later, a regulator requests evidence—the operator retrieves the object, hashes it, and matches it to the onchain receipt to prove the record hasn't been altered.
Akave Cloud is an enterprise-grade, distributed and scalable object storage designed for large-scale datasets in AI, analytics, and enterprise pipelines. It offers S3 object compatibility, cryptographic verifiability, immutable audit trails, and SDKs for agentic agents; all with zero egress fees and no vendor lock-in saving up to 80% on storage costs vs. hyperscalers.
Akave Cloud works with a wide ecosystem of partners operating hundreds of petabytes of capacity, enabling deployments across multiple countries and powering sovereign data infrastructure. The stack is also pre-qualified with key enterprise apps such as Snowflake and others.