


During 2023–2024, NVIDIA H100s faced 6–12 month waitlists. While supply has improved, hyperscalers continue to raise GPU prices while limiting availability for non-enterprise customers. For AI teams building production systems, compute access remains a primary constraint. And when you secure an allocation, egress fees and vendor lock-in turn every model checkpoint and dataset download into a budget negotiation.
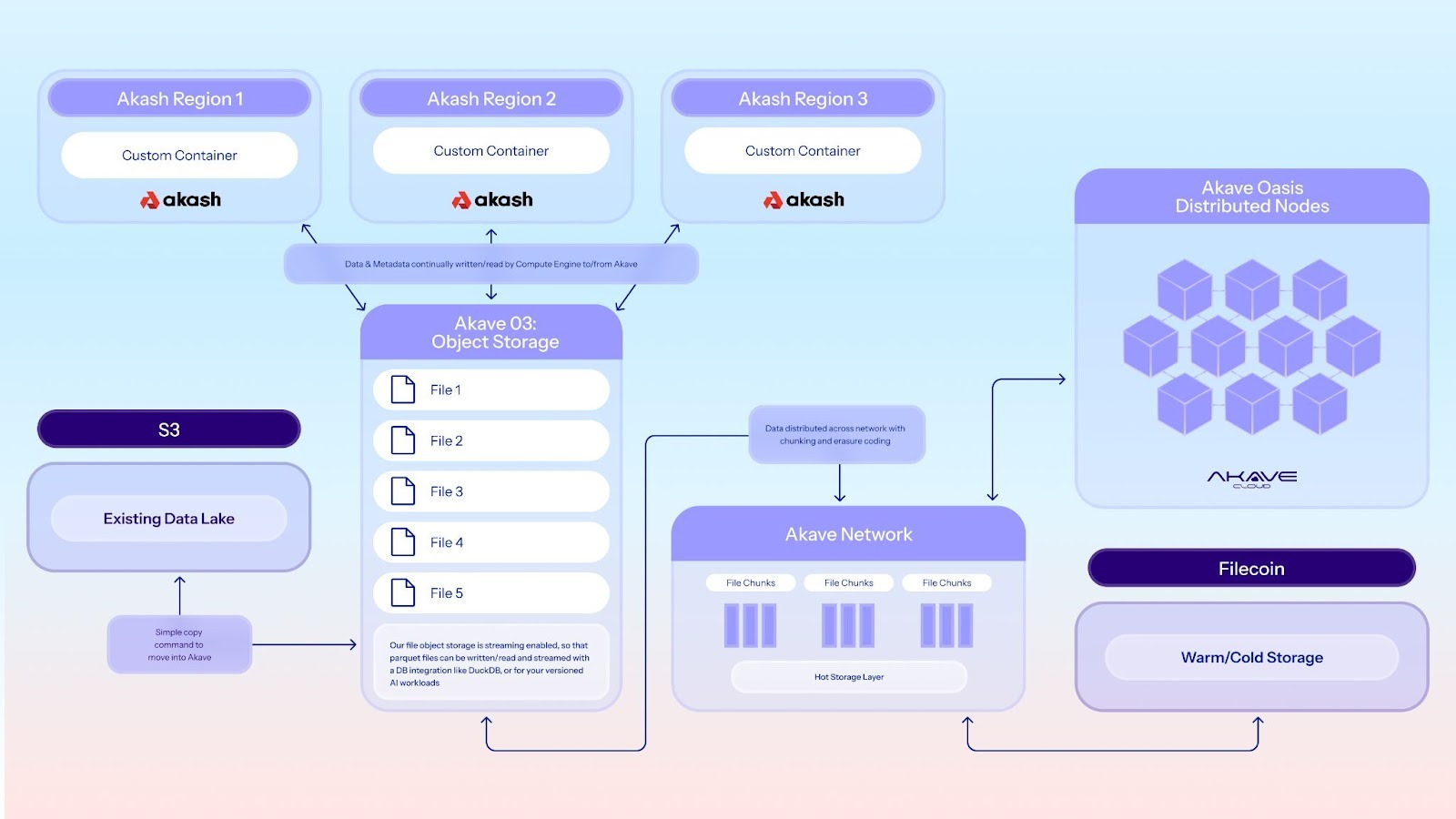
Akash Network, the world's first decentralized cloud computing marketplace, has integrated with Akave, the enterprise-grade decentralized object storage platform. The integration creates the first decentralized infrastructure stack to combine marketplace-allocated GPU compute with S3-compatible object storage that provides cryptographic verification of every write, without relying on centralized cloud providers. Training and inference run on Akash's 1,000+ GPUs. Checkpoints, logs, models, and model artifacts get stored on Akave's verifiable, blockchain-backed network. GPU-rich compute at 70–85% below hyperscaler rates (pricing varies by GPU type and marketplace demand). S3-compatible storage with zero egress fees. The entire workflow operates outside centralized cloud control.
This is infrastructure built for teams that get both performance and sovereignty, without relying on centralized allocation gatekeepers.
Integration Overview: S3-Compatible Storage, Kubernetes-Native Compute
Akash Network operates a decentralized compute marketplace with over 1,000 GPUs (H200, H100, A100, and B200/B300 launching soon) distributed across 65+ global datacenters. In 2025 alone, the network processed over 3.1 million deployments, maintaining 60% GPU utilization (industry-leading efficiency). Developers deploy workloads using SDL (Stack Definition Language), a YAML-based configuration familiar to any Kubernetes user.
AI workloads need more than compute. Model training generates massive checkpoint files. Inference APIs require low-latency access to embeddings and weights. Data pipelines move terabytes between preprocessing, training, and evaluation stages. Centralized clouds solve this with a monolithic architecture provided by a single vendor, then charge egress fees that can exceed compute costs.
Akave provides the missing piece: S3-compatible decentralized storage with cryptographic verification, client-side encryption, and zero egress fees. Data written to Akave uses 32,16 Reed-Solomon erasure coding for 11 nines of durability, and backed by Filecoin archival storage. Every write generates an onchain receipt. Every retrieval is cryptographically verifiable. And because Akave operates on flat-rate pricing ($14.99/TB/month with no per-request fees), there's no financial penalty for accessing your own data.
Integration maturity: The Akash + Akave integration is documented and available for deployment, with early adopters validating the joint architecture for AI training and storage workflows.
How It Works
The integration is built into the deployment architecture. Akash deployments configure Akave endpoints via environment variables in SDL files (AKAVE_ENDPOINT, AKAVE_BUCKET, AKAVE_ACCESS_KEY). Containers connect using standard S3 SDKs (boto3, AWS CLI, JavaScript libraries) without code changes.
Deployment workflow in three stages:
- Data staging & compute provisioning: Upload datasets to Akave buckets. Define Akash SDL file specifying GPU requirements, Akave credentials, and container image. Deployment takes under 2 minutes.
- Training & checkpointing: Container pulls training data from Akave via S3 GET requests. Zero egress fees mean pulling 500GB or 2TB costs exactly $0. During training, stream checkpoints back to Akave. If the job crashes, restart from the last stored checkpoint.
- Inference reuse: Deploy separate Akash inference service. Load model weights from Akave at startup, serve predictions, log results back to Akave. Storage API response times stay under 200ms (p95) globally.
Self-hosted option: Teams with strict data residency requirements can deploy Akave's O3 gateway as a self-hosted service. The O3 gateway runs in customer infrastructure, encrypts data client-side, and distributes it across the Akave network. The customer controls the gateway, owns the encryption keys, and defines access policies.
What You Get: 70% Lower Training Bills, Zero-Surprise Storage Costs, Onchain Proof of Every Write
Cost Efficiency Without Compromise
Akash H100 pricing at $1.14/hour (median marketplace rates as of Jan 2026, vs AWS p5.48xlarge H100 at $4.33/hour, us-east-1, on-demand pricing). For newer H200 GPUs, Akash pricing averages $2.82/hour. Training a 70B parameter model runs for under $10,000 on Akash.
Akave storage costs $14.99/TB/month with zero egress fees and zero per-request API charges. A team moving 10TB/month between training jobs and inference deployments pays $149.90 for storage. On hyperscaler S3, the same usage generates $900 in egress fees (AWS charges $0.09/GB for inter-region data transfer × 10,000 GB), before accounting for API request charges.
Real customer impact: Passage, a virtual events platform, migrated their GPU workloads to Akash and achieved 50–70% cost reduction while maintaining or improving performance. The migration completed in under 4 weeks because Akash uses standard containerization.
Joint stack adoption: The Akash + Akave integration is in early access, with pilot deployments validating the architecture for AI training and storage workflows.
Data Sovereignty and Verifiability
Hyperscalers promise 99.999999999% durability in their SLAs. Akave's 32,16 erasure coding architecture is designed for 11 nines of durability, with cryptographic proof of shard distribution you can verify yourself.
Every write operation to Akave generates a cryptographic receipt stored onchain. The receipt includes the data hash, timestamp, erasure coding parameters, and storage node distribution. Anyone can verify that the data was written, when it was written, and that it hasn't been modified since.
Client-side encryption means data encrypts before it leaves your infrastructure. Akave never sees plaintext. Even if a storage node is compromised, an attacker gets encrypted shards that are mathematically useless without the customer-held decryption keys.
For teams in regulated industries (healthcare, financial services, government contractors), this shifts the compliance conversation. Instead of trusting providers to implement HIPAA controls correctly, you deploy infrastructure where the architecture implements technical controls for compliance. Data residency? Geofencing enforces it in code. Audit trails? Onchain receipts provide them automatically.
Performance at Global Scale
Akash operates 65+ datacenters globally, enabling low-latency deployments near end users. Paired with Akave's distributed storage network, this creates edge-native infrastructure. An AI inference API deployed in Singapore pulls model weights from Akave nodes in the same region, serves predictions with sub-200ms end-to-end latency (p95, typical inference workloads), and logs requests back to geographically distributed storage, all without touching a centralized cloud.
Content moderation systems processing user uploads. Autonomous vehicle perception pipelines. Financial fraud detection. These workloads can't tolerate 500ms+ latency. Decentralized infrastructure isn't just cheaper. It's architecturally better for edge AI.
S3 Compatibility Means Zero Learning Curve
Akash uses SDL (which compiles to Kubernetes manifests) instead of proprietary deployment formats. Akave implements the S3 API instead of inventing a new object storage protocol. This eliminates the "decentralized tax" where teams spend weeks learning blockchain-specific tooling before deploying anything.
If your infrastructure team knows Kubernetes and S3, they can deploy on this stack today. No wallet setup. No gas fee budgeting. No learning Solidity. JWT authentication means developers authenticate with GitHub or Google SSO. Done.
“The closed cloud has become a gatekeeper to innovation, using GPU scarcity and predatory egress fees to lock developers into their ecosystems. By pairing Akash’s marketplace-allocated compute with Akave’s verifiable, zero-egress storage, we are delivering the final piece of the sovereign AI puzzle. This integration allows AI teams to break free from the ‘hyperscaler tax’ and build on a high-performance Supercloud where they, and not a single vendor, own their data, their models, and their future.”— Greg Osuri, Founder and CEO, Akash Network
“We’re excited to partner with Akash and put control back in users’ hands in a truly sovereign way: run compute on Akash, store on Akave, and verify every artifact end-to-end, without hyperscaler lock-in or egress games.”— Stefaan Vervaet, CEO, Akave
The AI Infrastructure Crisis This Partnership Solves
The AI boom created three simultaneous infrastructure crises that this integration directly addresses.
The GPU shortage forced startups into 6–12 month waitlists for NVIDIA hardware. Enterprises with deep pockets secured allocations, but mid-market companies building production AI applications faced a hard constraint: you can't train models without GPUs, and centralized clouds can't provision them fast enough. Akash's decentralized marketplace aggregates GPU capacity from datacenter operators, university research clusters, and regional infrastructure providers into production-grade compute. The network maintains 60% GPU utilization because supply isn't constrained by a single vendor's allocation decisions.
Egress fee exploitation turned data access into a profit center for centralized clouds. Training a large language model generates hundreds of checkpoint files. Moving data between training, validation, and inference environments can exceed compute costs. Teams architect around egress fees: keeping everything in one region, avoiding multi-cloud strategies, accepting vendor lock-in as the price of avoiding ruinous data transfer bills. Akave's zero egress pricing eliminates this architectural constraint.
Energy grid constraints emerged as the hard physical limit on AI scaling. By late 2025, hyperscalers began hitting local power capacity, forcing them to delay datacenter expansions and throttle GPU deployments. Decentralized compute distributes load geographically, matching AI workloads to available energy capacity instead of forcing all compute through mega-datacenters approaching their power limits.
Deploy Your First Training Job in 15 Minutes
What should you try first? Start with a non-critical training job: a model fine-tuning experiment or a weekend hackathon project. Use Akash's $100 free compute credits to deploy an H100 instance ($1.14/hr = 87 hours of H100 time). Configure Akave as your checkpoint storage. Run the training job end-to-end and compare performance + cost to your last bill. Track three metrics: deployment speed (Akash averages under 2 minutes), training throughput (compare GPU utilization), and total cost including storage egress (Akave charges $0 for data movement). Most teams see 70%+ savings on this first experiment, which builds confidence for production migration.
For developers and infrastructure teams: Full integration guide here, including SDL configurations and S3 API patterns.
Run the TCO calculation: Akash H100 GPUs at $1.14/hour or H200 GPUs at $2.82/hour (vs hyperscaler H100 on-demand at $4.33/hour). Akave storage at $14.99/TB/month with zero egress fees. Most AI workloads see 70%+ cost savings when combining both.
Start deploying on Akash (new users receive $100 in compute credits).
Create your Akave storage account at Akave.com
FAQ
What is "sovereign AI infrastructure" in plain English?
Sovereign AI infrastructure means you control your compute and data without intermediaries. With centralized clouds, you request GPU allocations from account teams, accept their pricing, and trust their storage SLAs. With Akash + Akave, you bid for GPUs on an open marketplace (no approval needed), store data with cryptographic verification (no trust required), and move workloads between providers using standard APIs (no lock-in). Sovereignty isn't just about decentralization. It's about maintaining operational independence and verifiable control over your AI stack.
If we already use hyperscalers for compute and storage, why switch?
You don't have to switch everything. Many teams use Akash for training (70–85% cost savings on H100s) and keep managed inference services, with Akave storage bridging both. The issue with full hyperscaler dependency is cost unpredictability (egress fees can exceed compute costs) and allocation constraints (GPU availability remains limited for non-enterprise accounts). Akash + Akave eliminate egress fees entirely and provide immediate GPU access via marketplace bidding. If your AI workload bills exceed $10k/month, you're likely overpaying by 70%+ for equivalent performance.
How does this work in practice for AI training workflows?
Your training pipeline stays the same. Only the infrastructure layer changes. You define an Akash SDL file (YAML format, similar to Kubernetes manifests) specifying GPU requirements, container image, and Akave storage credentials as environment variables. Deploy the SDL to Akash (takes under 2 minutes). The container pulls training data from Akave via standard S3 GET requests (boto3, AWS CLI), runs training, streams checkpoints back to Akave, and uploads final artifacts at completion. Model artifacts remain in Akave with on-chain verification receipts. If your code works with S3 and runs in containers, it works here.
Why does this matter for AI teams facing regulatory scrutiny or audits?
Emerging AI regulations (EU AI Act, proposed US frameworks) increasingly require provenance tracking: which data trained this model? When was it last updated? Who accessed training artifacts? Centralized cloud logs can be modified or deleted by the provider (or compelled by governments). Akave's on-chain receipts create an immutable audit trail for every dataset version, checkpoint file, and model artifact. Each write generates a cryptographic receipt stored on blockchain with data hash, timestamp, erasure coding parameters, and node distribution. During an audit, you don't reconstruct training history from CloudTrail logs. You provide blockchain-verified receipts that prove data lineage. For healthcare AI (HIPAA), financial AI (SOC 2), or government contractors (FedRAMP equivalents), this shifts compliance from "trust our controls" to "verify our cryptographic proof."
What about data residency and compliance controls?
Akave's O3 gateway can be self-hosted in your infrastructure (on-premises or specific geographic regions), giving you full control over where data is encrypted and stored. You define geofencing rules in code (e.g., "EU-only", "Frankfurt nodes only"), and the architecture enforces them automatically. Combined with Akash's distributed compute across 65+ global datacenters, you can keep both compute and storage within regulatory boundaries while maintaining cryptographic proof of compliance. Client-side encryption means data is encrypted before it leaves your infrastructure. Even if you use Akave's hosted gateway, you hold the encryption keys, so data residency concerns are addressed at the encryption layer, not just the storage layer. This architectural approach to compliance makes audits straightforward: point to geofencing configuration, show on-chain receipts for data placement, verify encryption keys remain in your custody.
Akave Cloud is an enterprise-grade, distributed and scalable object storage designed for large-scale datasets in AI, analytics, and enterprise pipelines. It offers S3 object compatibility, cryptographic verifiability, immutable audit trails, and SDKs for agentic agents; all with zero egress fees and no vendor lock-in saving up to 80% on storage costs vs. hyperscalers.
Akave Cloud works with a wide ecosystem of partners operating hundreds of petabytes of capacity, enabling deployments across multiple countries and powering sovereign data infrastructure. The stack is also pre-qualified with key enterprise apps such as Snowflake and others.